Input
- image
- predefined set of categories
Goal
Predict locations and identities of objects in that image similar to object detection, but rather than just predicting a bounding box for each of those objects, instead we want to predict a whole segmentation mask for each of those objects and predict which pixels in the input image corresponds to each object instance.
Instance Segmentation is a full problem, like a hybrid between semantic segmentation and object detection because like in object detection we can handle multiple objects and we differentiate the identities of different instances.
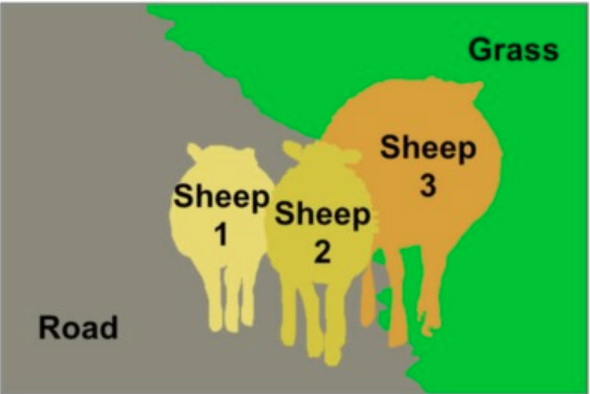 |
ROAD, SHEEP, SHEEP, SHEEP, GRASS
(Differentiate instances)
|
In the example above Instance Segmentation distinguishes between the three sheep instances.
The output is like in semantic segmentation where we have this pixel wise accuracy but here for each of these objects we also want to say which pixels belong to that object.
Method
The idea is to get region and classification predictions (for each object) and then apply semantic segmentation onto each of these regions.
Mask R-CNN
And this ends up looking a lot like Faster R-CNN.
So it has this multi-stage processing approach where we take our whole input image, that whole input image goes into some convolutional network and some learned region proposal network that's exactly the same as Faster R-CNN and now once we have our learned region proposals (input image goes through CNN - RPN) then we project those proposals onto our convolutional feature map just like we did in Fast and Faster R-CNN.
But now rather than just making a classification and a bounding box for regression decision
for each of those boxes we in addition want to predict a segmentation mask for each of those region proposals. So now it kind of looks like a semantic segmentation problem inside each of the region proposals that we're getting from our region proposal network.
 |
| Mask R-CNN Architecture Kaiming He Georgia Gkioxari Piotr Dollar Ross Girshick: Mask R-CNN |
After we do this RoI aligning to warp our features corresponding to the region of proposal
into the right shape, then we have two different branches.
First branch at the top looks just like Faster R-CNN and it will predict classification scores telling us what is the category corresponding to that region proposal or alternatively whether or not it's background. And we'll also predict some bounding box coordinates that regressed off the region proposal coordinates.
 |
| Mask R-CNN Architecture in detail Image source: Stanford University School of Engineering - Convolutional Neural Networks for Visual Recognition - Lecture 11 | Detection and Segmentation |
And now in addition we'll have this branch at the bottom which looks basically like a semantic segmentation mini network which will classify for each pixel in that input region proposal whether or not it's an object. This Mask R-CNN architecture just kind of unifies Faster R-CNN and Semantic Segmentation models into one nice jointly end-to-end trainable model.
It works really well, just look at the examples in the paper. They look kind of indistinguishable from ground truth.
Pose Estimation
Mask R-CNN also does pose estimation. You can do pose estimation by predicting these joint coordinates for each of the joints of the person.
Mask R-CNN can do joint object detection, pose estimation, and instance segmentation.
And the only addition we need to make is that for each of these region proposals we add an additional little branch that predicts these coordinates of the joints for the instance of the current region proposal.

Addition for pose estimation
Image source: Stanford University School of Engineering - Convolutional Neural Networks for Visual Recognition - Lecture 11 | Detection and Segmentation
As another layer has been added (another head coming out of the network) we need to add another loss to our multi-task loss.
Because it's built on the Faster R-CNN framework it runs relatively close to real time so this is running something like 5fps on a GPU because this is all sort of done in the single forward pass of the network.
Training
How much training data do you need?
All of these instant segmentation results were trained on the Microsoft Coco data set. Microsoft Coco is roughly 200,000 training images. It has 80 categories that it cares about so in each of those 200,000 training images it has all the instances of those 80 categories labeled. So there's something like 200,000 images for training and there's something like I think an average of five or six instances per image. So it actually is quite a lot of data. And for Microsoft Coco for all the people in Microsoft Coco they also have all the joints annotated as well so this actually does have quite a lot of supervision at training time. It is trained with quite a lot of data.
Training: Future improvements
One really interesting topic to study moving forward is that we kind of know that if you have a lot of data to solve some problem, at this point we're relatively confident that you can stitch up some convolutional network that can probably do a reasonable job at that problem but figuring out ways to get performance like this with less training data is a super interesting and active area of research.
That's something people will be spending a lot of their efforts working on in the next few years.
That's something people will be spending a lot of their efforts working on in the next few years.
No comments:
Post a Comment