I wanted to import a Northwind DB into my local instance of MySQL and found on one Google Code page a file with all necessary commands: Northwind.MySQL5.sql. I tried to execute it via MySQL Shell (mysqlsh) but got an error:
ERROR: 1064 (42000) at line 1: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '# ---------------------------------------------------------------------- #
#' at line 1
#' at line 1
After replacing the entire content of this sql file with simple
select User from mysql.user;
...I was still getting the same error. When running this command directly in SQL shell prompt, it was successful. But when passing the file via \source in the prompt or --file as mysqlsh argument, the error would appear. So something was wrong with the file or the way it's being passed to MySQL shell.
After some fruitless trials I created a new file and placed the same command and this time it worked fine!
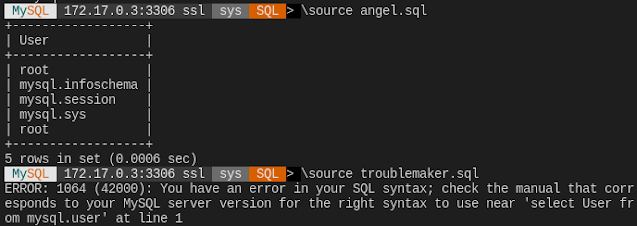
I then compared the HEX content of both files and I noticed the difference: troublemaker file was starting with Byte order mark (BOM) byte sequence: 0xefbbbf.

I could not find any document which confirms that MySQL shell does not ignore BOM in .sql files but I found the following:
mysql ignores Unicode byte order mark (BOM) characters at the beginning of input files. Previously, it read them and sent them to the server, resulting in a syntax error. Presence of a BOM does not cause mysql to change its default character set. To do that, invoke mysql with an option such as --default-character-set=utf8.
Seems that this is not the case for mysqlsh.
MySQL Shell’s JSON import utility importJSON() now
handles UTF-8 encoded files that include a BOM (byte mark
order) at the start, which is the sequence 0xEF 0xBB
0xBF. As a workaround in earlier releases, remove this
byte sequence, which is not needed. (Bug #30993547, Bug
#98836)
handles UTF-8 encoded files that include a BOM (byte mark
order) at the start, which is the sequence 0xEF 0xBB
0xBF. As a workaround in earlier releases, remove this
byte sequence, which is not needed. (Bug #30993547, Bug
#98836)
The MySQL implementation of UCS-2, UTF-16, and UTF-32 stores characters in big-endian byte order and does not use a byte order mark (BOM) at the beginning of values. Other database systems might use little-endian byte order or a BOM. In such cases, conversion of values needs to be performed when transferring data between those systems and MySQL. The implementation of UTF-16LE is little-endian.
MySQL uses no BOM for UTF-8 values.
Also make sure (since I use PHP and this had tripped me up a couple of times so I thought I'd mention it here) all your script files are UTF8 (without BOM)
“Table Data Import Wizard fails on UTF-8 encoded file with BOM.”
In any case, I came to conclusion that .sql files intended to be executed by MySQL should not start with BOM character.
We can remove BOM character as here:
$ sed -i '1s/^\xef\xbb\xbf//' troublemaker.sql
To check it:
$ xxd troublemaker.sql
00000000: 7365 6c65 6374 2055 7365 7220 6672 6f6d select User from
00000010: 206d 7973 716c 2e75 7365 723b mysql.user;
And finally, this troublemaker is not making troubles anymore:
MySQL 172.17.0.3:3306 ssl northwind SQL > \source troublemaker.sql
+------------------+
| User |
+------------------+
| root |
| mysql.infoschema |
| mysql.session |
| mysql.sys |
| root |
+------------------+
5 rows in set (0.0014 sec)
+------------------+
| User |
+------------------+
| root |
| mysql.infoschema |
| mysql.session |
| mysql.sys |
| root |
+------------------+
5 rows in set (0.0014 sec)